Parser une grammaire régulière en Python
Par Benjamin Delmée ![]() le 10.11.2019 (mis à jour le 06.12.2019)
le 10.11.2019 (mis à jour le 06.12.2019)
Toutes les analyses de données commencent par la récupération des données nécessaires à la conduite de l'analyse. Elles sont souvent extraites de systèmes existants puis sont stockées sous forme de fichiers plats (généralement CSV). Malheureusement les fonctions d'export des systèmes ne respectent pas toujours les règles du format CSV ce qui engendre des problèmes lors de la phase d'ingestion ou d'analyse.
Les anomalies les plus fréquentes sont :
- Les chaînes de caractères ne sont pas délimitées, ce qui engendre un décalage de colonnes lorsqu'elles contiennent un séparateur ou un split de la ligne lorsqu'elles contiennent un retour à la ligne
- Les délimiteurs de chaînes ne sont pas doublés, ce qui engendre une erreur d'interprétation lorsqu'une chaîne contient un délimiteur
Ces erreurs sont parfois difficiles à corriger. Plus grave encore, elles ne sont parfois pas détectées car les outils de data ingestion (comme Pandas) sont par défaut très tolérants et construisent des tables avec un nombre erroné de colonnes ou de lignes.
Fort heureusement on peut écrire un parseur de CSV qui vérifie automatiquement la conformité d'un fichier et nous donner la garantie que nos sources sont fiables ou nous aider à trouver les erreurs lorsqu'il y en a.
Représentation de la grammaire d'un fichier CSV via un graphe d'états-transitions
La grammaire d'un fichier CSV est décrite dans la RFC 4180. Elle est de type régulière, donc descriptible par un automate fini et déterministe (une version simplifiée d'une machine de Turing) :
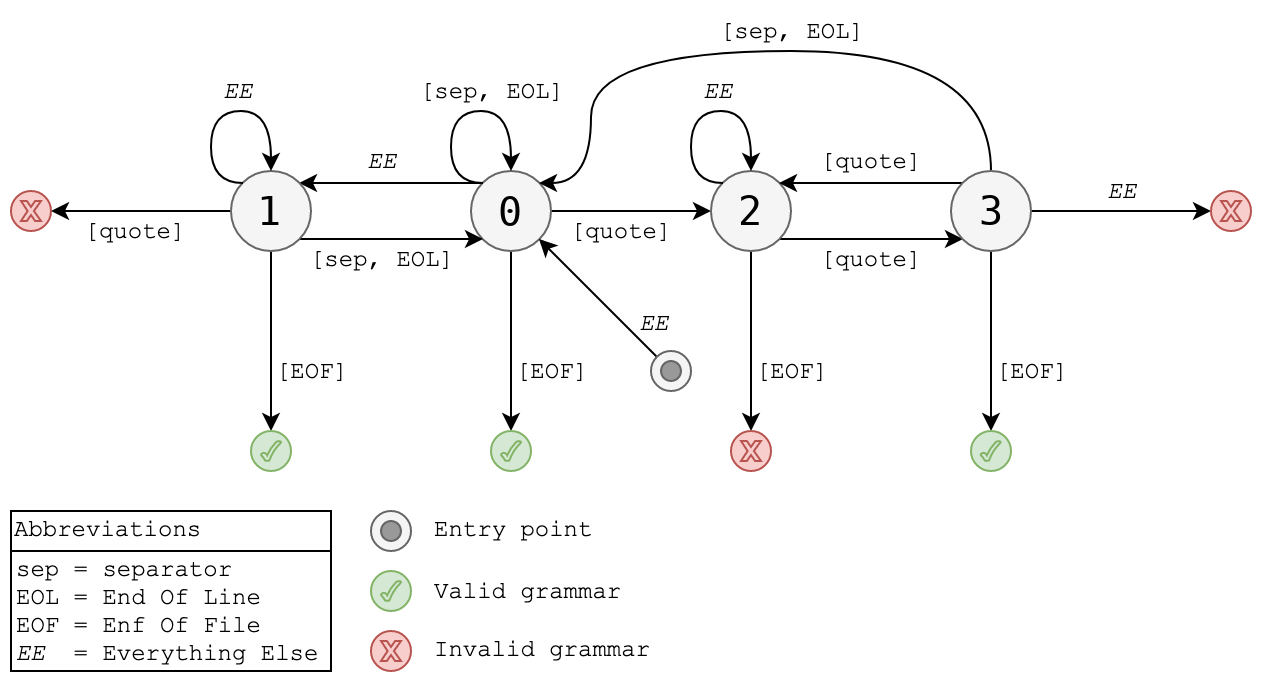
Ce graphe d'états-transitions fonctionne de la manière suivante : les caractères du fichier CSV sont lus un par un. À chaque lecture d'un nouveau caractère l'état courant est mis à jour en fonction de la règle de transition. Dans le cas où le fichier CSV est conforme à la RFC 4180, l'état final (c'est-à-dire l'état courant après la lecture du dernier caractère du fichier) sera l'état Valid Grammar.
Voici un exemple avec une ligne de fichier CSV non conforme :
200,"Susan"Smith",30
- L'automate est initialisé à l'état n°0
- À la lecture des caractères
200l'automate bascule dans l'état n°1 et boucle - À la lecture du caractère
,l'automate bascule dans l'état n°0 - À la lecture du caractère
"l'automate bascule dans l'état n°2 - À la lecture des caractères
Susanl'automate boucle sur l'état n°2 - À la lecture du caractère
"l'automate bascule dans l'état n°3 - À la lecture du caractère
Sl'automate bascule dans l'étatInvalid grammar
Explication : la RFC 4180 stipule que les délimiteurs de texte (ici ") compris dans les chaînes de caractères doivent être doublés pour éviter toute ambiguïté avec le délimiteur réel de fin de chaîne.
Implémentation du graphe états-transitions en Python
Le graphe d'états-transitions peut être implémenté simplement à l'aide d'une boucle et de quelques branchements conditionnels.
def is_valid(stream, sep, quotechar):
"""Tells if a stream respects the CSV grammar.
Returns: tuple(bool, int)
- (bool) True if the stream is valid, False otherwise
- (int) Number of the line where the syntax error lays, 0 if no error
"""
if quotechar is None:
# always True if the csv isn't escaped
return [True, 0]
cur_state = 0
for i, line in enumerate(stream):
line = line.strip('\r\n')
for char in line:
if cur_state == 0:
if char == quotechar:
cur_state = 2
elif char == sep:
pass
else:
cur_state = 1
elif cur_state == 1:
if char == sep:
cur_state = 0
elif char == quotechar:
return [False, i+1] # syntax error
else:
pass
elif cur_state == 2:
if char == quotechar:
cur_state = 3
else:
pass
elif cur_state == 3:
if char == quotechar:
cur_state = 2
elif char == sep:
cur_state = 0
else:
return [False, i+1] # syntax error
# end of the line reached
# equivalent of reaching \n character
if cur_state != 2:
cur_state = 0
# end of the stream reached
# equivalent of reaching EOF character
if cur_state == 2:
return [False, i+1] # syntax error
else:
return [True, 0]
csv_1 = ['700,"John Smith",45']
csv_2 = ['200,"Susan"Smith",30']
is_valid(csv_1, ',', '"')
>>> [True, 0]
is_valid(csv_2, ',', '"')
>>> [False, 1]
Bonus : Module Python
Ce code est disponible sous-forme d'un module Python, accessible depuis ce repository git : github.com/benjamindelmee/safe-csv.
Le module contient d'autres tests utiles aux data analystes comme par exemple :
- test si chaque ligne possède le même nombre de colonnes
- test si les noms de colonnes sont uniques
- test si les headers ne contiennent pas de caractères spéciaux
- ...
Le code est ouvert aux contributions.