Les fonctions de fenêtrage en SQL
Par Benjamin Delmée ![]() le 23.10.2019
le 23.10.2019
En SQL, les Window Functions (fonctions de fenêtrage) sont plus efficaces et plus lisibles que du code équivalent sans window functions. Elles sont aussi simples à comprendre (voir davantage) que l'opérateur GROUP BY mais sont, pourtant, trop peu utilisées. Détaillons leur fonctionnement pour remédier à cela.
À la manière du GROUP BY, les fonctions fenêtrées effectuent des calculs d'agrégations sur des paquets de lignes (qu'on appelle partitions). En revanche, une fois le calcul terminé, les lignes ne sont pas agrégées et le résultat du calcul est ajouté à toutes les lignes de la partition. Le nombre de lignes n'est donc pas modifié et le résultat de la requête contient autant de lignes que la table initiale.
Le code et les schémas ci-dessous illustrent la différence entre GROUP BY et fonctions de fenêtrage.
SELECT product, SUM(quantity), AVG(quantity)
GROUP BY product
FROM table;

Le GROUP BY a réduit le nombre final de lignes en agrégant les lignes par produit.
SELECT
product,
SUM(quantity) OVER(PARTITION BY product),
AVG(quantity) OVER(PARTITION BY product)
FROM
table;

La fonction de fenêtrage n'a pas réduit le nombre final de lignes. L'information a été dupliquée pour chaque ligne.
Un tel résultat peut être obtenu sans les fonctions de fenêtrage. Cependant la requête est plus concise et plus facilement optimisable par le moteur de rêquetes du SGBD. Pour s'en convaincre, voici un code équivalant au code ci-dessus mais qui n'utilise pas les fonctions de fenêtrage.
SELECT
A.product,
B.sum_quantity,
B.avg_quantity
FROM table AS A
LEFT JOIN (
SELECT
product,
SUM(quantity) AS sum_quantity,
AVG(quantity) AS avg_quantity
FROM table
GROUP BY product
) AS B ON A.product=B.product;
On constate que, même sur des fonctions simples telles que SUM ou AVG, la réécriture de la requête avec des fonctions de fenêtrage a permis un gain de lisibilité. Dans d'autres situations plus complexes (cf. la suite de cet article), les fonctions de fenêtrage deviennent encore plus indispensables.
Syntaxe des Window Functions

Comment utilise-t-on les fonctions de fenêtrage ? La clause OVER() définit la fenêtre sur laquelle la fonction doit s'appliquer. Les arguments optionnels suivants sont acceptés :
PARTITION BYpour définir la méthode de partitionnement. Si cette clause n'est pas mentionnée, la table entière est considérée comme unique partition.ORDER BYpour définir l'ordre à l'intérieur d'une partition. Si cette clause n'est pas mentionnée, aucun tri n'est effectué dans la fenêtre.
Les fonctions fenêtrées peuvent être de plusieurs natures. Voici ci-dessous quelques exemples de fonctions pour chaque type. Cette liste n'est pas exhaustive et peut varier d'un SGBD à l'autre. Vous devrez donc vous référencer à la documentation de votre SGBD.
- Fonctions d'agrégation (
SUM,MAX,COUNT, etc.) - Fonctions de rang (
RANK,ROW_NUMBER,CUME_DIST, etc.) - Fonctions de valeur (
FIRST_VALUE,LAG,LEAD, etc.)
Voyons quelques exemples pour chaque type de fonction.
Exemple de requêtes
Pour tous les exemples ci-dessous, supposons que notre base de données contienne la table transactions et que cette table référence l'historique des transactions immobilières dans le monde.
SELECT * FROM transactions;
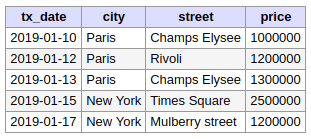
Fonction d'aggrégation : COUNT()
En plus des fonctions SUM et AVG qui ont déjà été présentées, on trouve également la fonction d'agrégation COUNT, très utile pour compter le nombre d'éléments dans une partition :
SELECT
T.*,
COUNT(*) OVER (PARTITION BY city) AS "Count of tx per city"
FROM
transactions AS T;
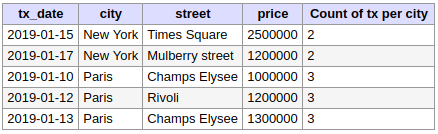
En ajoutant la clause ORDER BY à une fonction de type agrégation, on obtient un effet de cumulation. Dans cet exemple, on calcule la somme cumulée des prix par villes :
SELECT
T.*,
COUNT(*) OVER (PARTITION BY city ORDER BY price) AS "Cumulative Sum of Prices"
FROM
transactions AS T;
Fonctions de ranking : RANK() et DENSE_RANK()
La fonction RANK permet de créer un préordre (numérotation avec redondance) au sein d'une partition :
SELECT
T.*,
RANK() OVER (PARTITION BY city ORDER BY price) as "City price ranking"
FROM
transactions AS T;
![]()
À noter que la présence de la clause PARTITION BY n'est pas obligation. Si on l'omet, la fenêtre s'étendra sur l'ensemble de la table.
SELECT
T.*,
RANK() OVER (ORDER BY price) as "Global price ranking"
FROM
transactions AS T;
![]()
Dans cet exemple, on remarque que le rang de valeur 3 est absent (passage de 2 à 4). Cela s'explique par la colonne price qui contient deux fois la valeur 1200000.
Pour obtenir une numérotation contiguë, on utilise la fonction DENSE_RANK :
SELECT
T.*,
DENSE_RANK() OVER (ORDER BY price) as "Global price ranking"
FROM
transactions AS T;
![]()
Le rang 2 est toujours répété deux fois mais la numérotation a repris au rang 3. C'est pour cela que le rank est dense, il n'y a pas de rang manquant.
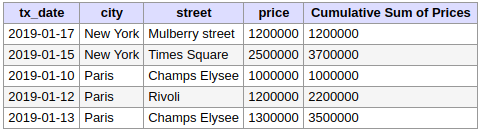
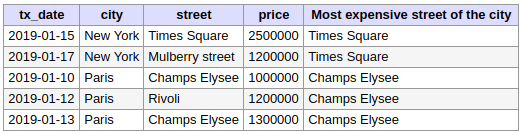
Fonctions valeurs : FIRST_VALUE() et LAG()
La fonction FIRST_VALUE permet de récupérer une valeur de la première ligne de la fenêtre. Un exemple de cas d'usage : connaître le montant de la première transaction boursière du jour (le "O" de OHLC).
Dans l'exemple suivant, on récupère pour chaque ville la rue avec la transaction au montant le plus élevé :
SELECT
T.*,
FIRST_VALUE(street) OVER (PARTITION BY city ORDER by city) AS "Most expensive street of the city"
FROM
transactions AS T;
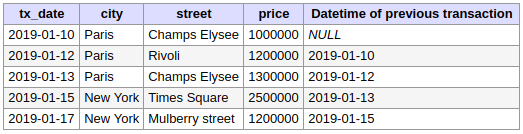
Une dernière fonction, très utile, permet de récupérer la ligne précédente. Dans cet exemple la fonction LAG est utilisée pour récupérer la date de la transaction précédente :
SELECT
T.*,
LAG(tx_date) OVER(ORDER BY tx_date) AS "Datetime of previous transaction"
FROM
transactions AS T;
À retenir
- Les fonctions de fenêtrage ont un fonctionnement proche de celui du
GROUP BY - Dans beaucoup de situations, elles sont plus performantes et plus lisibles que du code sans fonction de fenêtrage